
‘Delta Lake is the need of the present era. From the past several years, we have been hearing about DataLakes. I myself worked on several Data Lake implementations also. But the previous generation Data Lake was not a complete solution. One of the main fall backs in the old gen data lake is the difficulty in handling ACID transactions.
Delta Lake brings ACID transactions in the storage layer and thus makes the system more robust and efficient. One of my recent projects was to build a Data Lake for one of the India’s Largest Ride Sharing company. Their requirements include handling CDC (Change Data Capture) in the lake. Their customers make several rides per day and there will be lot of transactions and changes happening in various entities associated with the platform such as debiting money from wallet, crediting money to wallet, creating ride, deleting ride, updating ride, updating user profile etc.
The initial version of the Lake that I designed was capable of recording only the latest values of each of these entities. But that was not a proper solution as it will not bring the complete analytics capability. So after that I came up with a design using Delta that has the capability to handle the CDC. In this way we will be able to track all the changes happening to the data and also instead of updating the records, we will be keeping the historic data also in the system. 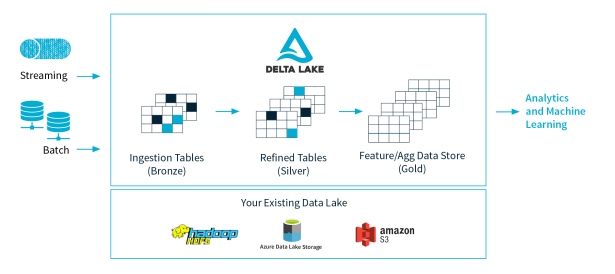
Image Credits: Delta Lake
The Delta format is the main magic behind the Delta Lake. The Delta format is open sourced by DataBricks and it is available with Apache Spark.
Some of the key features of Delta Lake are listed below.
- Support to ACID transactions. It is very tedious to bring data integrity in the conventional Data Lake. The transaction handling capability was missing in the old generation Data Lakes. With the support to transactions, the Delta Lake becomes more efficient and reduces the workload of Data Engineers.
- Data Versioning: Delta Lake supports time travel. This helps us for rollback, audit control, version control etc. In this way, the old records are not getting deleted instead it is getting versioned.
- Support for Merge, Update and Delete operations.
- No major change is required in the existing system to implement Delta Lake. Delta Lake is 100% open source and it is 100% compatible with the Spark APIs. The Delta Lake uses Apache Parquet format to store the data. The following snippet shows show to save data in Delta format. It is very simple, just use “delta” instead of “parquet”
dataframe
.write
.format("parquet")
.save("/dataset")
dataframe
.write
.format("delta")
.save("/dataset")
For trying out Delta in detail, use the community version of DataBricks
Sample code snippet for trying out the same is attached below.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| %python | |
| # Create a temparory dataset | |
| data = spark.range(0, 50) | |
| data.write.format("delta").save("/tmp/myfirst-delta-table") | |
| # Read the data | |
| df = spark.read.format("delta").load("/tmp/myfirst-delta-table") | |
| df.show() | |
| # Updating the dataset | |
| data = spark.range(51, 100) | |
| data.write.format("delta").mode("overwrite").save("/tmp/myfirst-delta-table") | |
| # Read the data | |
| df = spark.read.format("delta").load("/tmp/myfirst-delta-table") | |
| df.show() | |
| # Read the older version of data | |
| df = spark.read.format("delta").option("versionAsOf", 0).load("/tmp/myfirst-delta-table") | |
| df.show() |
